Label speech, sound, and silence with human-level accuracy, fast, multilingual, and ready to power your voice-enabled AI.
Audio Annotation Services
For Advanced AI Audio Analytics
Audio annotation involves labeling and tagging sound-based data, making it structured, searchable, and machine-readable. It is essential for AI applications such as speech recognition, sound classification, emotion detection, and multilingual translation systems.
Our expert annotators specialize in labeling spoken language, identifying speakers, transcribing conversations, and detecting background sounds to enhance AI-driven audio analytics. Using state-of-the-art audio annotation tools, we ensure high accuracy and reliability for AI-powered speech and sound recognition.
Need to annotate audio files USA-based for AI model training? Akademos provides tailored audio annotation solutions to meet your business needs.
Power Your Audio Data
Turn speech, sounds, and emotions into structured insights with our expert audio annotation
Identifies and labels specific sounds such as footsteps, alarms, sirens, or machinery noises, enabling AI to differentiate between various sound sources.
Applications: Security surveillance, environmental sound monitoring, context-aware AI systems.
Music Annotation
Labels and categorizes music streaming data, helping AI understand genres, instruments, and user preferences.
Applications: Recommendation engines, music categorization, content discovery.
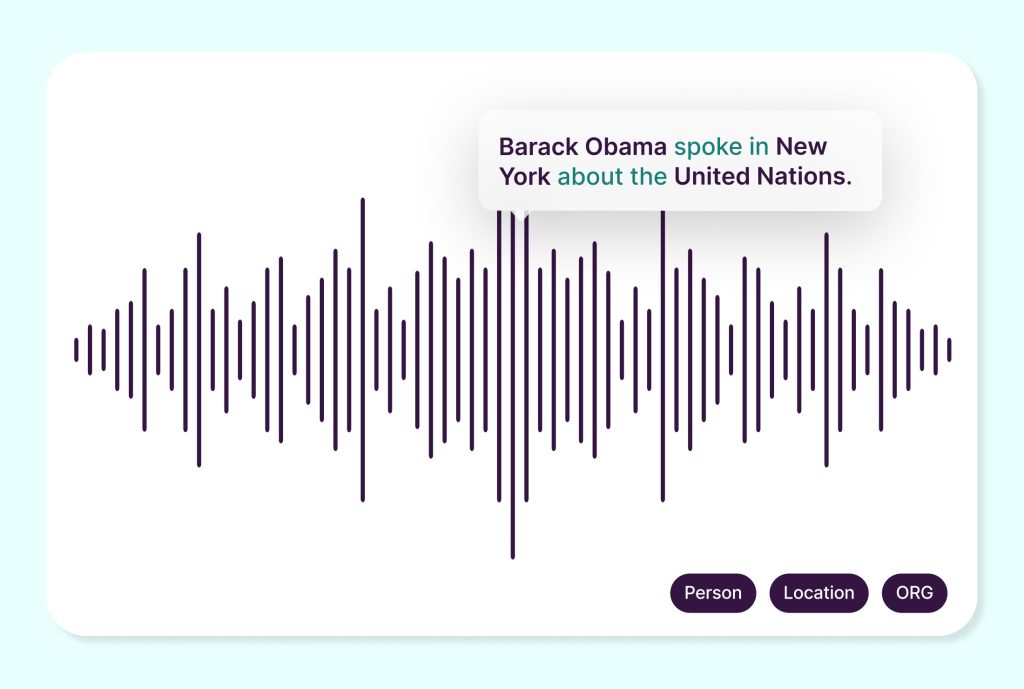
Named Entity Recognition (NER) for Audio
Recognizes and labels spoken entities such as names, locations, organizations, and key topics to improve voice search and AI-powered recommendations.
Focuses on labeling background and ambient sounds such as traffic noise, birds chirping, or crowd murmurs, enhancing AI’s ability to contextually analyze surroundings.
Applications: Smart city systems, noise monitoring, environmental AI solutions.